Streaming NEXRAD Level 2 Chunks from S3#
xradar can now ingest a list of NEXRAD Level 2 chunk byte objects directly, so you can stream real-time radar data from S3 without downloading full volume files first. This notebook demonstrates:
Listing and downloading chunk files from the
unidata-nexrad-level2-chunksbucketOpening a full volume assembled from all chunks
Handling partial volumes with
incomplete_sweep="drop"(default)Handling partial volumes with
incomplete_sweep="pad"Early streaming with just a few chunks
import warnings
import cmweather # noqa: F401 -- registers colormaps
import fsspec
import matplotlib.pyplot as plt
import numpy as np
import xradar as xd
Background: NEXRAD chunk files on S3#
NOAA publishes NEXRAD Level 2 data to two public S3 buckets:
Bucket |
Content |
Latency |
|---|---|---|
|
Complete volume files |
Minutes after scan |
|
Real-time chunk files |
Seconds after scan |
Each radar volume is split into many small chunk files that arrive as the radar scans. A volume directory typically contains:
One S (start) chunk that includes the volume header
Many I (intermediate) chunks with sweep data
One E (end) chunk marking the volume boundary
For example:
KABR/903/KABR20250717_120038_V06_S (start)
KABR/903/KABR20250717_120038_V06_I02 (intermediate)
KABR/903/KABR20250717_120038_V06_I03
...
KABR/903/KABR20250717_120038_V06_E (end)
xradar accepts a list of chunk bytes (or file paths, or file-like objects)
directly via open_nexradlevel2_datatree(). The chunks are concatenated
internally, so you never need to assemble them manually.
Load chunk data#
chunk_paths = []
try:
fs = fsspec.filesystem("s3", anon=True)
volumes = sorted(fs.ls("unidata-nexrad-level2-chunks/KABR/"))
if volumes:
chunk_paths = sorted(fs.ls(volumes[-1]))
except Exception:
pass
if chunk_paths:
print(f"Using live S3 chunks: {len(chunk_paths)} files")
for p in chunk_paths[:3]:
print(f" {p.split('/')[-1]}")
print(f" ... {chunk_paths[-1].split('/')[-1]}")
else:
print("S3 bucket empty or unreachable, using open-radar-data fixture")
/home/docs/checkouts/readthedocs.org/user_builds/xradar/conda/stable/lib/python3.13/site-packages/fsspec/registry.py:301: UserWarning: Your installed version of s3fs is very old and known to cause
severe performance issues, see also https://github.com/dask/dask/issues/10276
To fix, you should specify a lower version bound on s3fs, or
update the current installation.
warnings.warn(s3_msg)
Using live S3 chunks: 14 files
20260421-121521-001-S
20260421-121521-002-I
20260421-121521-003-I
... 20260421-121521-014-E
Download / load chunk bytes#
if chunk_paths:
all_bytes = [fs.open(p, "rb").read() for p in chunk_paths]
else:
import tarfile
from pathlib import Path
from open_radar_data import DATASETS
archive = DATASETS.fetch("nexrad_level2_chunks_KLOT.tar.gz")
with tarfile.open(archive) as tar:
tar.extractall("/tmp/nexrad_chunks", filter="data")
chunk_files = sorted(Path("/tmp/nexrad_chunks/nexrad_chunks_KLOT").iterdir())
all_bytes = [f.read_bytes() for f in chunk_files]
total_mb = sum(len(b) for b in all_bytes) / 1e6
print(f"Loaded {len(all_bytes)} chunks ({total_mb:.1f} MB total)")
Loaded 14 chunks (2.1 MB total)
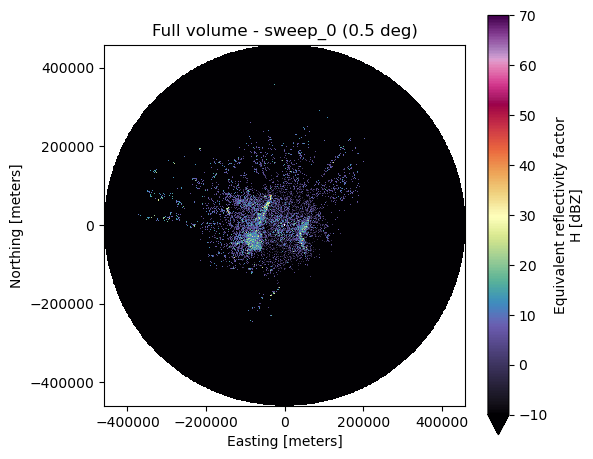
Full volume from all chunks#
When all chunks (S through E) are available, passing the list to
open_nexradlevel2_datatree produces the same result as opening a
complete volume file.
dtree = xd.io.open_nexradlevel2_datatree(all_bytes)
display(dtree)
/tmp/ipykernel_3954/601822868.py:1: UserWarning: Dropped 1 incomplete sweep(s): [2]. Use incomplete_sweep='pad' to include them with NaN-filled rays.
dtree = xd.io.open_nexradlevel2_datatree(all_bytes)
<xarray.DataTree>
Group: /
│ Dimensions: ()
│ Coordinates:
│ latitude float64 8B 45.46
│ longitude float64 8B -98.41
│ altitude int64 8B 421
│ Data variables:
│ volume_number int64 8B 0
│ platform_type <U5 20B 'fixed'
│ instrument_type <U5 20B 'radar'
│ time_coverage_start <U20 80B '2026-04-21T12:15:21Z'
│ time_coverage_end <U20 80B '2026-04-21T12:16:58Z'
│ Attributes: (12/25)
│ Conventions: None
│ instrument_name: KABR
│ version: None
│ title: None
│ institution: None
│ references: None
│ ... ...
│ avset_enabled: True
│ ebc_enabled: True
│ super_res_status: 2
│ rda_build_number: 2400
│ operational_mode: 4
│ actual_elevation_cuts: 3
├── Group: /sweep_0
│ Dimensions: (azimuth: 720, range: 1832)
│ Coordinates:
│ * azimuth (azimuth) float64 6kB 0.2444 0.7526 1.258 ... 359.3 359.8
│ elevation (azimuth) float64 6kB 0.4395 0.4395 ... 0.4395 0.4395
│ time (azimuth) datetime64[ns] 6kB ...
│ range (range) float32 7kB 2.125e+03 2.375e+03 ... 4.599e+05
│ Data variables:
│ DBZH (azimuth, range) float64 11MB ...
│ ZDR (azimuth, range) float64 11MB ...
│ PHIDP (azimuth, range) float64 11MB ...
│ RHOHV (azimuth, range) float64 11MB ...
│ CCORH (azimuth, range) float64 11MB ...
│ sweep_mode <U20 80B 'azimuth_surveillance'
│ sweep_number int64 8B 0
│ prt_mode <U7 28B 'not_set'
│ follow_mode <U7 28B 'not_set'
│ sweep_fixed_angle float64 8B 0.4834
│ Attributes:
│ waveform_type: contiguous_surveillance
│ channel_config: sz2_phase_coding
│ super_resolution: 11
│ sails_cut: False
│ sails_sequence_number: 0
│ mrle_cut: False
│ mrle_sequence_number: 0
│ mpda_cut: False
│ base_tilt_cut: False
└── Group: /sweep_1
Dimensions: (azimuth: 718, range: 1192)
Coordinates:
* azimuth (azimuth) float64 6kB 1.2 1.695 2.211 ... 359.2 359.7
elevation (azimuth) float64 6kB 0.4395 0.4395 ... 0.4395 0.4395
time (azimuth) datetime64[ns] 6kB ...
range (range) float32 5kB 2.125e+03 2.375e+03 ... 2.999e+05
Data variables:
DBZH (azimuth, range) float64 7MB ...
VRADH (azimuth, range) float64 7MB ...
WRADH (azimuth, range) float64 7MB ...
sweep_mode <U20 80B 'azimuth_surveillance'
sweep_number int64 8B 1
prt_mode <U7 28B 'not_set'
follow_mode <U7 28B 'not_set'
sweep_fixed_angle float64 8B 0.4834
Attributes:
waveform_type: contiguous_doppler
channel_config: sz2_phase_coding
super_resolution: 7
sails_cut: False
sails_sequence_number: 0
mrle_cut: False
mrle_sequence_number: 0
mpda_cut: False
base_tilt_cut: Falseds = xd.georeference.get_x_y_z(dtree["sweep_0"].to_dataset(inherit="all_coords"))
fig, ax = plt.subplots(figsize=(6, 5))
ds.DBZH.plot(x="x", y="y", cmap="ChaseSpectral", vmin=-10, vmax=70, ax=ax)
ax.set_title(f"Full volume - sweep_0 ({ds.sweep_fixed_angle.values:.1f} deg)")
ax.set_aspect("equal")
fig.tight_layout()
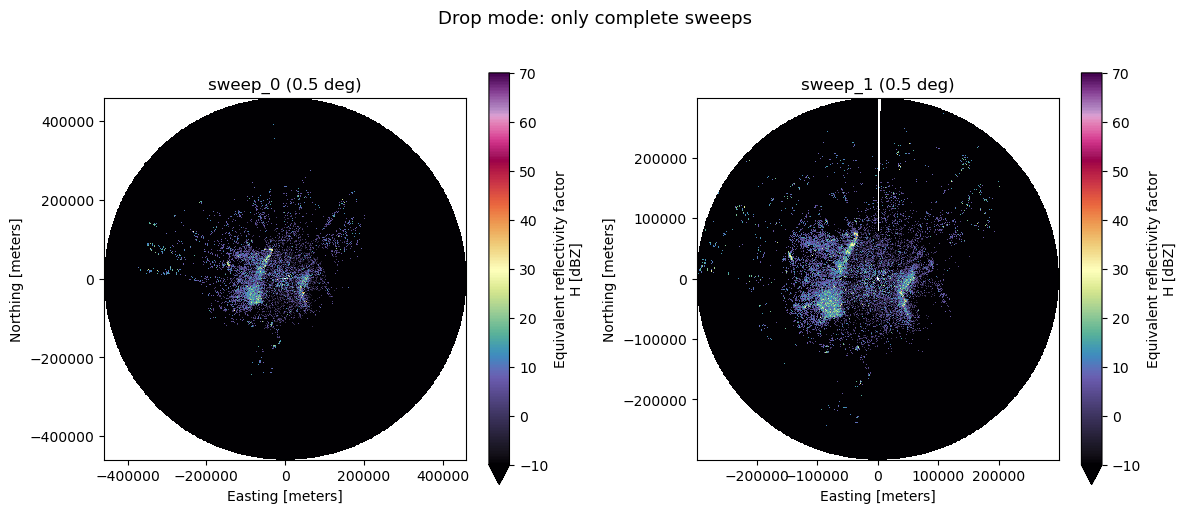
Partial volume – drop mode (default)#
When only some chunks have arrived, the last sweep is usually incomplete
(fewer rays than a full 360-degree rotation). By default,
incomplete_sweep="drop" excludes these partial sweeps and emits a warning.
This is the safest option for downstream processing that expects complete sweeps.
partial_chunks = all_bytes[:15]
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
dtree_drop = xd.io.open_nexradlevel2_datatree(
partial_chunks, incomplete_sweep="drop"
)
# Show warnings
for warning in w:
print(f"WARNING: {warning.message}")
sweep_groups = list(dtree_drop.match("sweep_*").keys())
print(f"\nSweeps kept: {sweep_groups}")
WARNING: Dropped 1 incomplete sweep(s): [2]. Use incomplete_sweep='pad' to include them with NaN-filled rays.
Sweeps kept: ['sweep_0', 'sweep_1']
if len(sweep_groups) >= 2:
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
for ax, grp in zip(axes, sweep_groups[:2]):
ds = xd.georeference.get_x_y_z(dtree_drop[grp].to_dataset(inherit="all_coords"))
ds.DBZH.plot(x="x", y="y", cmap="ChaseSpectral", vmin=-10, vmax=70, ax=ax)
ax.set_title(f"{grp} ({ds.sweep_fixed_angle.values:.1f} deg)")
ax.set_aspect("equal")
fig.suptitle("Drop mode: only complete sweeps", y=1.02, fontsize=13)
fig.tight_layout()
elif len(sweep_groups) == 1:
fig, ax = plt.subplots(figsize=(6, 5))
ds = xd.georeference.get_x_y_z(
dtree_drop[sweep_groups[0]].to_dataset(inherit="all_coords")
)
ds.DBZH.plot(x="x", y="y", cmap="ChaseSpectral", vmin=-10, vmax=70, ax=ax)
ax.set_title(f"{sweep_groups[0]} ({ds.sweep_fixed_angle.values:.1f} deg)")
ax.set_aspect("equal")
fig.suptitle("Drop mode: only complete sweeps", y=1.02, fontsize=13)
fig.tight_layout()
else:
print("No complete sweeps in 15 chunks (all dropped).")
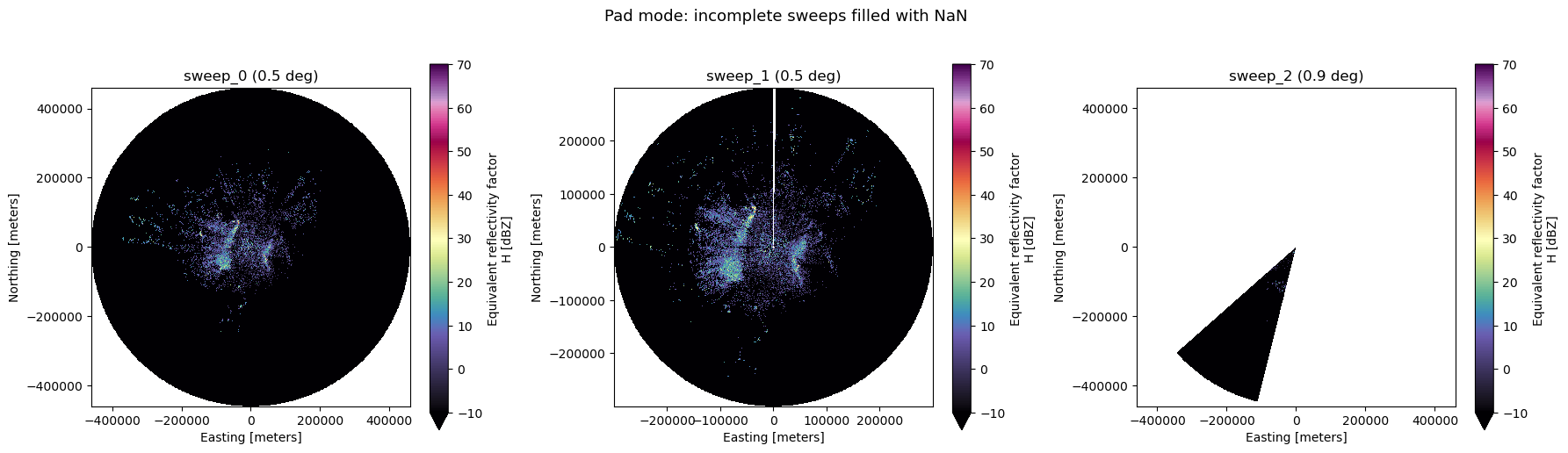
Partial volume – pad mode#
With incomplete_sweep="pad", incomplete sweeps are kept and reindexed
to a full azimuth grid. Missing rays are filled with NaN. The angular
resolution (0.5 or 1.0 degree) is auto-detected from the data.
This is useful for visualization and monitoring where you want to see all available data as soon as it arrives.
dtree_pad = xd.io.open_nexradlevel2_datatree(partial_chunks, incomplete_sweep="pad")
sweep_groups_pad = list(dtree_pad.match("sweep_*").keys())
print(f"Sweeps available (pad mode): {sweep_groups_pad}")
# Show NaN percentage in each sweep
for grp in sweep_groups_pad:
ds = dtree_pad[grp].to_dataset()
if "DBZH" in ds:
nan_pct = np.isnan(ds.DBZH.values).mean() * 100
print(f" {grp}: azimuth size={ds.sizes['azimuth']}, DBZH NaN={nan_pct:.1f}%")
Sweeps available (pad mode): ['sweep_0', 'sweep_1', 'sweep_2']
sweep_0: azimuth size=720, DBZH NaN=0.0%
sweep_1: azimuth size=718, DBZH NaN=0.0%
sweep_2: azimuth size=720, DBZH NaN=90.4%
n_sweeps = len(sweep_groups_pad)
fig, axes = plt.subplots(1, n_sweeps, figsize=(6 * n_sweeps, 5))
if n_sweeps == 1:
axes = [axes]
for ax, grp in zip(axes, sweep_groups_pad):
ds = xd.georeference.get_x_y_z(dtree_pad[grp].to_dataset(inherit="all_coords"))
ds.DBZH.plot(x="x", y="y", cmap="ChaseSpectral", vmin=-10, vmax=70, ax=ax)
ax.set_title(f"{grp} ({ds.sweep_fixed_angle.values:.1f} deg)")
ax.set_aspect("equal")
fig.suptitle("Pad mode: incomplete sweeps filled with NaN", y=1.02, fontsize=13)
fig.tight_layout()
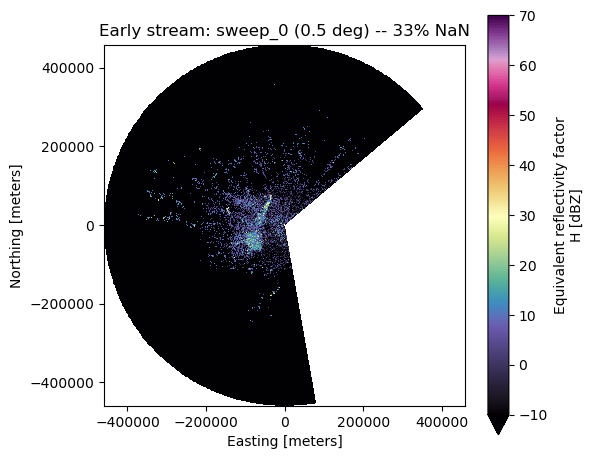
Early streaming – few chunks#
Even with only 5 chunks (before the first sweep completes), pad mode shows the partial data that has arrived. The NaN wedge makes it clear which azimuths are still missing.
early_chunks = all_bytes[:5]
dtree_early = xd.io.open_nexradlevel2_datatree(early_chunks, incomplete_sweep="pad")
sweep_groups_early = list(dtree_early.match("sweep_*").keys())
print(f"Sweeps from 5 chunks: {sweep_groups_early}")
if sweep_groups_early:
ds = xd.georeference.get_x_y_z(
dtree_early[sweep_groups_early[0]].to_dataset(inherit="all_coords")
)
nan_pct = np.isnan(ds.DBZH.values).mean() * 100
print(f"DBZH NaN percentage: {nan_pct:.1f}%")
fig, ax = plt.subplots(figsize=(6, 5))
ds.DBZH.plot(x="x", y="y", cmap="ChaseSpectral", vmin=-10, vmax=70, ax=ax)
ax.set_title(
f"Early stream: {sweep_groups_early[0]} "
f"({ds.sweep_fixed_angle.values:.1f} deg) -- {nan_pct:.0f}% NaN"
)
ax.set_aspect("equal")
fig.tight_layout()
else:
print("No sweeps found in 5 chunks.")
/home/docs/checkouts/readthedocs.org/user_builds/xradar/conda/stable/lib/python3.13/site-packages/xradar/util.py:466: UserWarning: Rays might miss on beginning and/or end of sweep. `a1gate` information is needed to fully recover. We'll assume sweep start at first valid ray.
warnings.warn(
Sweeps from 5 chunks: ['sweep_0']
DBZH NaN percentage: 33.3%
Summary#
Scenario |
|
Behavior |
|---|---|---|
Full volume (all chunks) |
|
All sweeps present, no difference |
Partial volume |
|
Incomplete sweeps excluded, warning emitted |
Partial volume |
|
Incomplete sweeps kept, missing rays filled with NaN |
Early stream (few chunks) |
|
Single partial sweep visible with NaN wedge |
Note: Single-file, bytes, and file-like inputs continue to work exactly as
before. The list input and incomplete_sweep parameter are additive features.